Building A Queue - Part 1
For a while now, I've wanted to write my on queue. Not because I thought I could do a better job than the many options already available, but rather because I thought it might prove to be a good exercise. I've been doing so much in-memory work lately, that I felt increasingly ignorant about persistence patterns. And, when you think about it, what could be easier to implement than a simple queue?
The actual catalyst for me to start coding was NSQ. NSQ is a messaging platform that's easy to setup and use; it's the right kind of simple. That said, NSQ cannot guarantee message ordering and it was primarily designed to be in-memory. These limitations make sense for a certain class of events (like analytics), but they're tough to work with when using a queue as the core of loosely coupled systems.
With a couple configuration options, NSQ can be durable. But the implementation is such that performance degrades linearly with each new channel (a consumer). Why? because each channel gets a copy the message. With everything in-memory, this isn't a huge deal. But when persisted to disk, the linear demand for IO doesn't go unnoticed. The difference between 0, 5 and 10 channels, when writing 5000 4K messages, is 2.22s, 3.81s and 5.19s.
This made me start to think about how I'd design a queue for my own needs. Namely, I'm interested in guaranteed message ordering, at-least one delivery and durability. On the flip side, I don't care about high availability.
Staying with NSQ's approach, my queue has topics and channels. You write to, and create channels from, a topic. A topic might be named "v1.users", which has messages that capture whenever a user gets created, updated or deleted. Any job interested in these messages would create a channel, such as a "email welcomer", "referrer updater" and "cache purger".
The implementation relies on two types of file: segments and state. Each topic has one or more segment file and a single state file. The segment files have a small header and data. The most important part of the header is reference to the next segment file:

For the segment currently being written to, the next reference is blank. Segments are a lot like an intrusive singly linked list. The data portion is is made up of 32-bit length-prefixed messages. We create a new segment file once we reach a specific size (currently 16MB).
The single state file associates a channel name with a segment id and an offset within that segment:
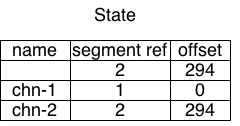
The first state entry represents the tail (where the next write will be written to). Together, a segment reference and offset point to a specific position within a distinct file.
We'll explore these files in greater detail in following posts. But there are a few things worth pointing out. First of all, aside from the messages themselves, a segment's next reference is the only other piece of information that we must sync to disk. As long as our data isn't corrupted and we have valid segment references, we can always walk, in order, through the queue and find the tail. This reduces the amount of forced syncs we need to do.
Furthermore, because segment ids are sequential, it's quite easy to determine if a segment can be deleted. As long as 1 channel currently references that segment, or a segment before it, we can't touch it.
Finally, because the state of each channel is a reference to, as opposed to copy of the data, the number of channels has no impact on the performance of the system. Inserting 5000 4K messages took 450ms with 0, 5 or 10 channels.
You can find the code at https://github.com/karlseguin/sq. It's untested and you shouldn't use it for anything serious.